 vs
vs 
What vehicle will take you from Berlin to Frankfurt quickest? A Caterham Super 7 (Lotus super7) or a double decker bus? The Autobahn has no speed limit so many think that the answer is obvious since the top speed of the Super7 can go much faster than the double-decker bus. But what if you need to take 50 people? or 100 people? The Caterham can only take two people at a time including the driver so you need to go quite a few rounds in order to bring all the people to Frankfurt. The bus will clearly win this challenge, unless you also compete with the ICE train or an airplane. As always, the question is not straight forward; it depends. Yes: It depends.
In the context of computers and virtualization; how do you know that your new shiny pieces of hardware that you're planning to buy is fast enough? How do you know that it will provide enough performance for your environment? There is really only one perfect way find out; and that is by moving your workload to the new hardware, and make sure to use the stop watch on your applications and services before and after the move.

If you’re unable to do that there are also other methods of generating workloads that will simulate a typical environment and give out some numbers based on the achieved performance. The tests I’ve been running in many of my previous blog postings has showed the usage of iometer from a single VM. While iometer is a great tool, the usage of only a single VM to put some load on the system will not be able to reflect the typical workload in a manner spread across multiple hosts and storage devices like your real system would do. VMware have however developed a benchmark that takes care of this: VMmark. It is a set of virtual machines similar to what a typical company uses including Apache web servers, Microsoft Exchange and several databases.
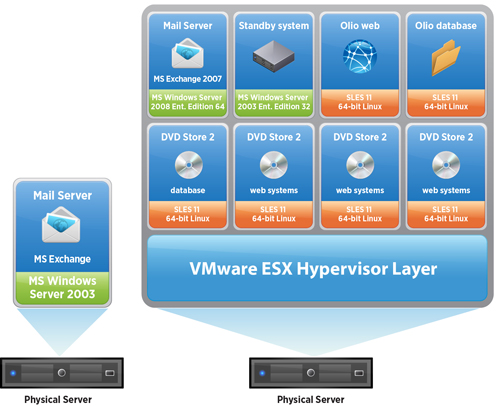

VMmark will give a good test of the capabilities of different workloads of a system, and the numbers will let you compare the system to others who have run the test before. VMmark also looks at all core four resources (cpu, memory, disk io, network io) when performing real world tests. VMmark is however not something that is setup in just a few minutes. It’s takes quite some time to put all the pieces in place since it’s not provided as a vApp or by .ovf/.ova files, but requires manual setup and installation of both Windows and SUSE Linux VMs.
Setting up VMmark is actually a quite complicated taks. Most average admins has neither time or competence to set up every little component that is needed by VMmark. They also typically want to get some results as quickly as possible in order to confirm whether the performance is ok or not.
There is a range of tools available and while there have historically been benchmarks for physical servers like SiSoft Sandra, 3DMark/Futuremark, CPU-Z, Everest and others. These will normally not easily give the numbers you’re looking for in a virtual environment. In a virtual environment all resources are shared, and the devices are virtual. This means that the gpu tests will yield very bad results, and the cpu features presented may not match the ones available giving strange results. Timing may also be an issue. As these tests are created for generating maximum load on devices on a single physical computer, they are created for testing the racing car. Our ESX servers are double-decker buses getting a lot more done than a small car even though the small car may be better for special tasks. Some may want to convert VMs with bad performance into physical hosts, but that is really to take one step back instead of trying to solve the problem. Keep also in mind that virtual machines are superior to physical ones.

In a virtual environment, the performance areas are typically related in this particular order:
If we where giving each of these a weight, my take on this (if the hardware used is recent) is that the sum of point 1 and 2 would probably be 75% of the total. Networking and CPU are also important, but are rarely the cause of performance problems. If your storage is networking based, then the performance of this network is also very important (see #2).
Memory
So how can you tell if you have enough memory? Well, if the guest OS is swapping, then you have not given it enough memory. If VMware is using the balloon driver inside the guest, it may indicate that you either have a situation with planned overcommitted memory and are running fine or that you are running out of memory and the system is actively using both the balloon driver and perhaps also VMware swap. VMware swap is the last resort that VMware will use to solve low memory problems. The alternative would be less VMs on the system and you would be unable to start more. Swapping memory to disk is usually very bad since a spinning disk is 1000 times slower than conventional memory and while VMware is using a tax based scheme, the performance will often be noticably slower. By using solid state disks you can actually get better performance also when swapping, but most systems are still not equipped or setup for such situations. What about memory speed? Well.. Memory chips run at different speeds, but as memory is like 10000x faster than the storage system, it’s not very likely that the memory speed is causing a noticable bottle neck.

What about VMs that are larger than a NUMA node? Well, it could slow down things slightly, but it's not normally the cause why memory is important when searching for performance. The most crucial thing is to have enough memory. If you’re running out of memory, the system will use disk instead. A spinning disk is much much slower than memory. Some say 1000x, some say 10000x. I don't know what is the right factor, only that it’s very true that disk is much much slower than real memory/RAM. Solid state disks are however different and will make this gap smaller.
Storage
It could be a good idea to use iometer or a similar tool to get a baseline of how your system performs. If you have no idea what the numbers you get from iometer means you can search for others with a similar system as you and check if their iometer results are similar to yours. If your numbers are not close to the numbers others have got, you probably have a system that is not setup optimally and should try to figure out what you can do to tune your system to get better performance.

There are of course also other tools such as vdbench, bonnie++, iozone, etc that can be used to baseline io on your system. Some of these tools can generate different load from many VMs, trying to simulate a live environment much more realistically than iometer will do easily. Such a tool will require some configuration and if setup correctly generate a load pattern that resembles a live environment.
Also note that the load from a typical live VMware environment is normally a fairly random pattern. This because you have multiple physical hosts with many VMs that are accessing the same LUNs at the same time.
For maximum performance it's recommended to use the paravirtualized PVSCSI adapter.
You may use esxtop from VMware and perfmon / vmstat inside the guests to monitor the performance.
Network
Network could also be a the bottle neck. Of the most common reasons why we find the network to be a bottle neck is that the physical switches are not configured correctly, that the nic/switch is using a buggy firmware or a faulty cable. It's also very important that the network is segmented correctly, either physically or with different VLANs and QoS. This because certain operations such as vMotion will push the network load to the maximum. If you're using the traditional standard vSwitch, the only way to separate the traffic is to use enough nics to get them separated. With the new VMware Distributed Switch (VDS) you can use Load Based Teaming with NetIOC to achieve this with fewer nics.
The newest and greatest paravirtualized network adapter, vmxnet3 is also recommended for maximum performance.
If your doing your storage over the network the history is of course very different as network will then be equally important as storage.
Newer servers are shipped with 10GbE nics and if you're using VDS (or Cisco Nexus 1000v) you can often get away by using only two nics. If you're using the good old standard VMware vSwitch you need to use more physical nics in order to achieve good separation.
CPU
Even though cpu is the bottom at this list it could still be the bottle neck. Modern cpus tend to have many cores and they have added support for virtualization natively. This means that modern cpus are much better than older ones. A few years ago cpu could be a common bottle neck as well and we could often point it out by reading the value of the cpu ready counter.You can still read the value of this counter, but it's now rare to find high values here unless you have done something highly unusual (like having many more vcpus compared to lcpus).
Keep in mind that if all of the above in this list is having great performance, cpu is likely to be the bottle neck as both storage io, network io and memory access needs cpu power as fuel.
You can easily add more vcpus to a VM, but it's also worth noting that you should not give your VMs more vcpus than they need as extra vcpus also adds some overhead to your system and may affect the overall performance negatively. Not all applications or services are written to utilize more than a single or maybe a few cpus and then it would be wise to only give such VMs only the number of vcpus that they require.
To monitor the cpu performance you can also use the standard tools provided by VMware combined with the ones provided by the guest OS.
Summary
When going from Berlin to Frankfurt it's normally best to use a bus unless you only have a single passenger. When running virtual machines it's also similar. An ESX host can give you much better aggregated performance while it can also normally give each VM all the resources it needs. We also know that if the VMs need more resources than a single host can provide, DRS will reschedule VMs in order to give the requested performance. Paravirtualized adapters are normally recommended and you can monitor performance from both inside the VMs, from the vsphere client and from esxtop.
Further reading
In the context of computers and virtualization; how do you know that your new shiny pieces of hardware that you're planning to buy is fast enough? How do you know that it will provide enough performance for your environment? There is really only one perfect way find out; and that is by moving your workload to the new hardware, and make sure to use the stop watch on your applications and services before and after the move.

If you’re unable to do that there are also other methods of generating workloads that will simulate a typical environment and give out some numbers based on the achieved performance. The tests I’ve been running in many of my previous blog postings has showed the usage of iometer from a single VM. While iometer is a great tool, the usage of only a single VM to put some load on the system will not be able to reflect the typical workload in a manner spread across multiple hosts and storage devices like your real system would do. VMware have however developed a benchmark that takes care of this: VMmark. It is a set of virtual machines similar to what a typical company uses including Apache web servers, Microsoft Exchange and several databases.
VMmark will give a good test of the capabilities of different workloads of a system, and the numbers will let you compare the system to others who have run the test before. VMmark also looks at all core four resources (cpu, memory, disk io, network io) when performing real world tests. VMmark is however not something that is setup in just a few minutes. It’s takes quite some time to put all the pieces in place since it’s not provided as a vApp or by .ovf/.ova files, but requires manual setup and installation of both Windows and SUSE Linux VMs.
Setting up VMmark is actually a quite complicated taks. Most average admins has neither time or competence to set up every little component that is needed by VMmark. They also typically want to get some results as quickly as possible in order to confirm whether the performance is ok or not.
There is a range of tools available and while there have historically been benchmarks for physical servers like SiSoft Sandra, 3DMark/Futuremark, CPU-Z, Everest and others. These will normally not easily give the numbers you’re looking for in a virtual environment. In a virtual environment all resources are shared, and the devices are virtual. This means that the gpu tests will yield very bad results, and the cpu features presented may not match the ones available giving strange results. Timing may also be an issue. As these tests are created for generating maximum load on devices on a single physical computer, they are created for testing the racing car. Our ESX servers are double-decker buses getting a lot more done than a small car even though the small car may be better for special tasks. Some may want to convert VMs with bad performance into physical hosts, but that is really to take one step back instead of trying to solve the problem. Keep also in mind that virtual machines are superior to physical ones.

In a virtual environment, the performance areas are typically related in this particular order:
- Enough memory
- Storage (including storage network)
- Networking
- CPU
If we where giving each of these a weight, my take on this (if the hardware used is recent) is that the sum of point 1 and 2 would probably be 75% of the total. Networking and CPU are also important, but are rarely the cause of performance problems. If your storage is networking based, then the performance of this network is also very important (see #2).
Memory
So how can you tell if you have enough memory? Well, if the guest OS is swapping, then you have not given it enough memory. If VMware is using the balloon driver inside the guest, it may indicate that you either have a situation with planned overcommitted memory and are running fine or that you are running out of memory and the system is actively using both the balloon driver and perhaps also VMware swap. VMware swap is the last resort that VMware will use to solve low memory problems. The alternative would be less VMs on the system and you would be unable to start more. Swapping memory to disk is usually very bad since a spinning disk is 1000 times slower than conventional memory and while VMware is using a tax based scheme, the performance will often be noticably slower. By using solid state disks you can actually get better performance also when swapping, but most systems are still not equipped or setup for such situations. What about memory speed? Well.. Memory chips run at different speeds, but as memory is like 10000x faster than the storage system, it’s not very likely that the memory speed is causing a noticable bottle neck.

What about VMs that are larger than a NUMA node? Well, it could slow down things slightly, but it's not normally the cause why memory is important when searching for performance. The most crucial thing is to have enough memory. If you’re running out of memory, the system will use disk instead. A spinning disk is much much slower than memory. Some say 1000x, some say 10000x. I don't know what is the right factor, only that it’s very true that disk is much much slower than real memory/RAM. Solid state disks are however different and will make this gap smaller.
Storage
It could be a good idea to use iometer or a similar tool to get a baseline of how your system performs. If you have no idea what the numbers you get from iometer means you can search for others with a similar system as you and check if their iometer results are similar to yours. If your numbers are not close to the numbers others have got, you probably have a system that is not setup optimally and should try to figure out what you can do to tune your system to get better performance.

There are of course also other tools such as vdbench, bonnie++, iozone, etc that can be used to baseline io on your system. Some of these tools can generate different load from many VMs, trying to simulate a live environment much more realistically than iometer will do easily. Such a tool will require some configuration and if setup correctly generate a load pattern that resembles a live environment.
Also note that the load from a typical live VMware environment is normally a fairly random pattern. This because you have multiple physical hosts with many VMs that are accessing the same LUNs at the same time.
For maximum performance it's recommended to use the paravirtualized PVSCSI adapter.
You may use esxtop from VMware and perfmon / vmstat inside the guests to monitor the performance.
Network
Network could also be a the bottle neck. Of the most common reasons why we find the network to be a bottle neck is that the physical switches are not configured correctly, that the nic/switch is using a buggy firmware or a faulty cable. It's also very important that the network is segmented correctly, either physically or with different VLANs and QoS. This because certain operations such as vMotion will push the network load to the maximum. If you're using the traditional standard vSwitch, the only way to separate the traffic is to use enough nics to get them separated. With the new VMware Distributed Switch (VDS) you can use Load Based Teaming with NetIOC to achieve this with fewer nics.
The newest and greatest paravirtualized network adapter, vmxnet3 is also recommended for maximum performance.
If your doing your storage over the network the history is of course very different as network will then be equally important as storage.
Newer servers are shipped with 10GbE nics and if you're using VDS (or Cisco Nexus 1000v) you can often get away by using only two nics. If you're using the good old standard VMware vSwitch you need to use more physical nics in order to achieve good separation.
CPU
Even though cpu is the bottom at this list it could still be the bottle neck. Modern cpus tend to have many cores and they have added support for virtualization natively. This means that modern cpus are much better than older ones. A few years ago cpu could be a common bottle neck as well and we could often point it out by reading the value of the cpu ready counter.You can still read the value of this counter, but it's now rare to find high values here unless you have done something highly unusual (like having many more vcpus compared to lcpus).
Keep in mind that if all of the above in this list is having great performance, cpu is likely to be the bottle neck as both storage io, network io and memory access needs cpu power as fuel.
You can easily add more vcpus to a VM, but it's also worth noting that you should not give your VMs more vcpus than they need as extra vcpus also adds some overhead to your system and may affect the overall performance negatively. Not all applications or services are written to utilize more than a single or maybe a few cpus and then it would be wise to only give such VMs only the number of vcpus that they require.
To monitor the cpu performance you can also use the standard tools provided by VMware combined with the ones provided by the guest OS.
Summary
When going from Berlin to Frankfurt it's normally best to use a bus unless you only have a single passenger. When running virtual machines it's also similar. An ESX host can give you much better aggregated performance while it can also normally give each VM all the resources it needs. We also know that if the VMs need more resources than a single host can provide, DRS will reschedule VMs in order to give the requested performance. Paravirtualized adapters are normally recommended and you can monitor performance from both inside the VMs, from the vsphere client and from esxtop.
Further reading
No comments:
Post a Comment