WARNING: Do not try this at home. Call VMware Support! Only those who are lucky, brave and immortal you may consider continuing reading this post. Don't forget to take offline snapshots of your SDDC Manager appliance before you do anything.
Background
VMware Cloud Foundation (VCF) 5.2 supports stretched vSAN clusters across two availability zones (AZs). Expanding a stretched cluster with new hosts is one of these tasks that you can't do from the GUI, but need to do REST calls against the API instead.
When expanding such a cluster by adding newly prepared hosts, you use the POST /v1/clusters/{clusterId}/expand API endpoint. Broadcom's official documentation describes the required JSON spec, but as we discovered, it's missing a critical field that will cause the operation to fail every time in certain environments.
When expanding such a cluster by adding newly prepared hosts, you use the POST /v1/clusters/{clusterId}/expand API endpoint. Broadcom's official documentation describes the required JSON spec, but as we discovered, it's missing a critical field that will cause the operation to fail every time in certain environments.
Environment
- VCF Version: 5.2.2.0 Build 24936865
- Cluster type: vSAN Stretched Cluster across two AZs
- AZ1 hosts: Management VLAN 100, Network Pool CORP-AZ1
- AZ2 hosts: Management VLAN 200, Network Pool CORP-AZ2
- Fault domains: CORP-CLUSTER01_primary-az-faultdomain (AZ1) and CORP-CLUSTER01_secondary-az-faultdomain (AZ2)
- Goal: Add 2 hosts to each fault domain (4 hosts total)
What the documentation says
Broadcom's official documentation for adding hosts to a stretched cluster shows this spec structure:
{
"clusterExpansionSpec": {
"hostSpecs": [ {
"id": "ESXi host 1 ID",
"licenseKey": "XXXXX-XXXXX-XXXXX-XXXXX-XXXXX",
"azName":"primary/secondary",
"hostNetworkSpec": {
"vmNics": [{
"id": "vmnic0",
"vdsName": "<vSphere Distributed Switch 1>"
},
{
"id": "vmnic1",
"vdsName": "<vSphere Distributed Switch 2>"
}
]
}
}
...Straightforward enough. We followed this exactly, matching each host to its correct fault domain based on VLAN. It failed within 15 minutes of processing.
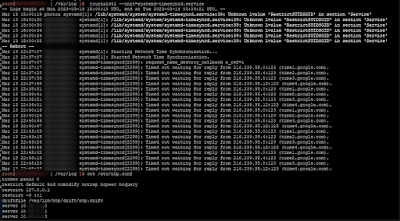
The error
The GUI shows the following:

And the domainmanager log file reveals a few more details:
And the domainmanager log file reveals a few more details:
HOST_NETWORK_VALIDATION_FAILED
Host corpesxi01.corp.local VlanId 100 is not same as availability zones VlanId 200
The log from ValidateExpandStretchHostNetworkAction told the full story:
ERROR Host corpesxi01.corp.local VlanId 100 is not same as availability zones VlanId 200
DEBUG Getting service credential with entity ID <AZ2-host-uuid>
INFO Host params: ip: 10.10.200.11, username: svc-vcf-corpesxi03
DEBUG Connecting to https://corpesxi03.corp.local:443/sdk
The validator was reporting a failure for an AZ1 host, but immediately connecting to an AZ2 host (corpesxi03) to perform the check. It was reading the expected VLAN from the wrong availability zone's existing host; comparing an AZ1 host (VLAN 100) against the VLAN it read from an AZ2 host (VLAN 200).
This seems to be a bug in ValidateExpandStretchHostNetworkAction.java in VCF 5.2.2. When no networkPoolId is provided in the spec, the validator attempts to determine the expected management VLAN by connecting to an existing host already in the target fault domain. Due to a scoping issue, it sometimes selects a host from the wrong fault domain, causing the VLAN comparison to fail regardless of how correct your azName mapping is.
Solution: Add networkPoolId to hostNetworkSpec
The solution is to explicitly provide the networkPoolId in each host's hostNetworkSpec. This gives the validator a direct reference to look up the expected VLAN from the network pool definition, bypassing the broken host-lookup logic entirely.
First, retrieve your network pool IDs:
$headers = @{ Authorization = "Bearer $token" }
$pools = Invoke-RestMethod -Method Get `
-Uri "https://sddc-manager.corp.local/v1/network-pools" `
-Headers $headers
$pools.elements | ForEach-Object {
Write-Host "Pool: $($_.name) ID: $($_.id)"
}
Pool: CORP-AZ1 ID: aaaaaaaa-1111-2222-3333-bbbbbbbbbbbb
Pool: CORP-AZ2 ID: cccccccc-4444-5555-6666-dddddddddddd
Then verify which hosts belong to which pool before building your spec:
Invoke-RestMethod -Method Get `
-Uri "https://sddc-manager.corp.local/v1/hosts?status=UNASSIGNED_USEABLE" `
-Headers $headers |
Select-Object -ExpandProperty elements |
Select-Object id, fqdn,
@{N="vlan"; E={($_.networks | Where-Object {$_.type -eq "MANAGEMENT"}).vlanId}},
@{N="pool"; E={$_.networkpool.name}} |
Format-Table -AutoSize
Example output:
id fqdn vlan pool
-- ---- ---- ----
aaaaaaaa-0001-0001-0001-000000000001 corpesxi05.corp.local 100 CORP-AZ1
aaaaaaaa-0001-0001-0001-000000000002 corpesxi06.corp.local 100 CORP-AZ1
aaaaaaaa-0001-0001-0001-000000000003 corpesxi07.corp.local 200 CORP-AZ2
aaaaaaaa-0001-0001-0001-000000000004 corpesxi08.corp.local 200 CORP-AZ2
Now build the corrected spec with networkPoolId included:
{
"clusterExpansionSpec": {
"hostSpecs": [
{
"id": "aaaaaaaa-0001-0001-0001-000000000001",
"licenseKey": "XXXXX-XXXXX-XXXXX-XXXXX-XXXXX",
"azName": "CORP-CLUSTER01_primary-az-faultdomain",
"hostNetworkSpec": {
"networkPoolId": "aaaaaaaa-1111-2222-3333-bbbbbbbbbbbb",
"vmNics": [
{ "id": "vmnic0", "vdsName": "CORP-VDS001" },
{ "id": "vmnic2", "vdsName": "CORP-VDS001" }
]
}
},
{
"id": "aaaaaaaa-0001-0001-0001-000000000002",
"licenseKey": "XXXXX-XXXXX-XXXXX-XXXXX-XXXXX",
"azName": "CORP-CLUSTER01_primary-az-faultdomain",
"hostNetworkSpec": {
"networkPoolId": "aaaaaaaa-1111-2222-3333-bbbbbbbbbbbb",
"vmNics": [
{ "id": "vmnic0", "vdsName": "CORP-VDS001" },
{ "id": "vmnic2", "vdsName": "CORP-VDS001" }
]
}
},
{
"id": "aaaaaaaa-0001-0001-0001-000000000003",
"licenseKey": "XXXXX-XXXXX-XXXXX-XXXXX-XXXXX",
"azName": "CORP-CLUSTER01_secondary-az-faultdomain",
"hostNetworkSpec": {
"networkPoolId": "cccccccc-4444-5555-6666-dddddddddddd",
"vmNics": [
{ "id": "vmnic0", "vdsName": "CORP-VDS001" },
{ "id": "vmnic2", "vdsName": "CORP-VDS001" }
]
}
},
{
"id": "aaaaaaaa-0001-0001-0001-000000000004",
"licenseKey": "XXXXX-XXXXX-XXXXX-XXXXX-XXXXX",
"azName": "CORP-CLUSTER01_secondary-az-faultdomain",
"hostNetworkSpec": {
"networkPoolId": "cccccccc-4444-5555-6666-dddddddddddd",
"vmNics": [
{ "id": "vmnic0", "vdsName": "CORP-VDS001" },
{ "id": "vmnic2", "vdsName": "CORP-VDS001" }
]
}
}
]
}
}Key takeaway
The mapping rule is simple:
| Host VLAN | Network Pool | azName |
networkPoolId |
|---|---|---|---|
| VLAN 100 | CORP-AZ1 | primary-az-faultdomain |
AZ1 pool UUID |
| VLAN 200 | CORP-AZ2 | secondary-az-faultdomain |
AZ2 pool UUID |
Always verify VLAN <-> pool <-> fault domain mapping before submitting by querying /v1/hosts?status=UNASSIGNED_USEABLE and cross-referencing with /v1/network-pools. The networkPoolId field is not documented as required in the Broadcom docs for VCF 5.2.2, but omitting it triggers a validator bug that causes the operation to fail with a misleading VLAN mismatch error.
Cleaning up stuck tasks before trying again
When this process fails you will nead to clean up stuck subtasks before trying again with a json file as described above. You will get ~69 subtasks that you can see as Pending in the GUI of SDDC Manager.

It *is* possible to do it manually, but after repeatedly trying to fix this issue I rather did a small shell script to speed up the process. The following script is talking directly to the local postgres domainmanager database. Such operations are potensially dangerous. Deleting the main task is possible through the API, but the subtasks are still stuck. Use with caution and double check your backups:
#!/bin/bash
# vcf-cleanup-stuck-tasks.sh
# Cleans up INITIALIZED (stuck) processing_task records in VCF domainmanager DB
# Usage: ./vcf-cleanup-stuck-tasks.sh [execution_id]
# If no execution_id is provided, cleans up the latest EXPAND_STRETCHED_CLUSTER run
set -euo pipefail
PGHOST="localhost"
PGUSER="postgres"
PGDB="domainmanager"
PSQL="psql -h $PGHOST -U $PGUSER -d $PGDB -t -A"
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
CYAN='\033[0;36m'
NC='\033[0m'
log() { echo -e "${CYAN}[INFO]${NC} $*"; }
ok() { echo -e "${GREEN}[OK]${NC} $*"; }
warn() { echo -e "${YELLOW}[WARN]${NC} $*"; }
err() { echo -e "${RED}[ERROR]${NC} $*"; exit 1; }
# ── Resolve execution ID ──────────────────────────────────────────────────────
if [[ $# -ge 1 ]]; then
EXEC_ID="$1"
log "Using provided execution ID: $EXEC_ID"
else
log "No execution ID provided — looking up latest EXPAND_STRETCHED_CLUSTER..."
EXEC_ID=$($PSQL -c "
SELECT id FROM execution
WHERE name = 'EXPAND_STRETCHED_CLUSTER'
ORDER BY start_time DESC
LIMIT 1;
" 2>/dev/null | head -1)
[[ -z "$EXEC_ID" ]] && err "No EXPAND_STRETCHED_CLUSTER execution found in DB."
log "Found latest execution: $EXEC_ID"
fi
# ── Verify execution exists and is in a terminal state ───────────────────────
EXEC_STATUS=$($PSQL -c "
SELECT execution_status FROM execution WHERE id = '$EXEC_ID';
" 2>/dev/null | head -1)
[[ -z "$EXEC_STATUS" ]] && err "Execution ID '$EXEC_ID' not found in database."
if [[ "$EXEC_STATUS" == "IN_PROGRESS" ]]; then
err "Execution $EXEC_ID is still IN_PROGRESS — will not cancel subtasks of a running workflow."
fi
log "Execution status: $EXEC_STATUS"
# ── Show current task status breakdown ───────────────────────────────────────
echo ""
log "Current processing_task status breakdown:"
$PSQL -c "
SELECT status, COUNT(*) as count
FROM processing_task
WHERE execution_id = '$EXEC_ID'
GROUP BY status
ORDER BY count DESC;
" 2>/dev/null | column -t -s '|'
echo ""
# ── Count INITIALIZED tasks ───────────────────────────────────────────────────
INIT_COUNT=$($PSQL -c "
SELECT COUNT(*) FROM processing_task
WHERE execution_id = '$EXEC_ID'
AND status = 'INITIALIZED';
" 2>/dev/null | head -1)
if [[ "$INIT_COUNT" -eq 0 ]]; then
ok "No INITIALIZED tasks found — nothing to clean up."
exit 0
fi
warn "Found $INIT_COUNT INITIALIZED (stuck) tasks for execution $EXEC_ID"
# ── Confirm ───────────────────────────────────────────────────────────────────
read -r -p "$(echo -e "${YELLOW}Cancel these $INIT_COUNT tasks and restart domainmanager? [y/N]:${NC} ")" CONFIRM
[[ "${CONFIRM,,}" != "y" ]] && { warn "Aborted by user."; exit 0; }
# ── Cancel stuck tasks ────────────────────────────────────────────────────────
log "Cancelling $INIT_COUNT INITIALIZED tasks..."
UPDATED=$($PSQL -c "
UPDATE processing_task
SET status = 'CANCELLED'
WHERE execution_id = '$EXEC_ID'
AND status = 'INITIALIZED';
" 2>/dev/null | grep -oP '\d+' | head -1 || echo "0")
ok "Cancelled $UPDATED tasks."
# ── Verify ────────────────────────────────────────────────────────────────────
echo ""
log "Updated status breakdown:"
$PSQL -c "
SELECT status, COUNT(*) as count
FROM processing_task
WHERE execution_id = '$EXEC_ID'
GROUP BY status
ORDER BY count DESC;
" 2>/dev/null | column -t -s '|'
echo ""
# ── Restart domainmanager ─────────────────────────────────────────────────────
log "Restarting domainmanager.service..."
systemctl restart domainmanager.service
log "Waiting 30 seconds for service to come up..."
sleep 30
STATUS=$(systemctl is-active domainmanager.service)
if [[ "$STATUS" == "active" ]]; then
ok "domainmanager.service is running."
else
err "domainmanager.service failed to start (status: $STATUS). Check: journalctl -u domainmanager.service -n 50"
fi
echo ""
ok "Cleanup complete. Verify the SDDC Manager UI task list is clear before resubmitting."

.Name -Name VirtualCenter.VimPasswordExpirationInDays")